O erro mais comum: tratar SLA como cadastro e não como rotina
Muitas operações configuram um prazo padrão e assumem que isso, por si só, resolve o problema. Na prática, SLA só funciona quando a equipe enxerga o prazo no contexto do trabalho diário: o que entrou, o que está em risco e o que precisa de ação imediata.
Sem visibilidade contínua, a fila acumula tickets críticos ao lado de chamados simples. O resultado é previsível: atrasos recorrentes, priorização improvisada e dificuldade para justificar desempenho para a liderança.
No contexto de tickets, SLA pode ser aplicado por fila, categoria, prioridade, impacto, horário de atendimento e regra operacional. Demandas simples podem ter prazos diferentes de demandas críticas. Tickets internos podem ter metas diferentes de tickets externos. O importante é que o prazo reflita a realidade da operação.
- Separar regras por tipo de demanda reduz distorções
- Alertar antes do atraso é mais útil do que reagir depois
- Métrica de SLA precisa estar conectada à leitura do fluxo
Como estruturar uma política que faça sentido na operação
O melhor ponto de partida é mapear os cenários que realmente exigem tempos diferentes. Em geral, fila, prioridade, impacto e categoria já resolvem boa parte da lógica sem criar uma estrutura excessivamente complexa.
A política precisa refletir a realidade da capacidade da equipe. Definir metas irreais só aumenta o volume de estouro e tira credibilidade do indicador. O objetivo não é cadastrar o prazo mais curto possível, e sim construir um compromisso operacional que seja monitorável.
Escolher o tipo certo depende do problema. Se a queixa é falta de retorno, comece pela primeira resposta. Se a queixa é demora para resolver, priorize resolução. Se o problema é ticket parado entre áreas, use SLA por etapa ou automações de escalonamento.
- Criar políticas por criticidade e contexto do ticket
- Usar alertas progressivos para antecipar desvio
- Acompanhar backlog e risco por fila
- SLA por etapa.
- SLA por fila ou categoria.
O que a gestão deve acompanhar além do prazo bruto
Cumprimento de SLA sozinho não conta toda a história. Uma fila pode ter boa taxa de resolução e, ainda assim, esconder gargalos em tickets críticos ou atraso de primeira resposta. É por isso que a leitura ideal combina taxa de cumprimento, tempo médio, itens em risco e volume por status.
Quando a operação acompanha esses sinais em conjunto, a conversa deixa de ser apenas "quantos tickets atrasaram" e passa a responder "onde o fluxo está travando, por quê e qual ação corrige a rota".
Também é importante revisar o SLA depois da implantação. Os primeiros relatórios mostram se os prazos foram realistas. Uma taxa de estouro muito alta pode indicar sobrecarga ou meta mal calibrada. Uma taxa sempre perfeita pode indicar que o prazo está folgado demais para orientar prioridade.
- Considere horário útil.
- Separe prioridades reais.
- Evite prazos únicos para tudo.
- Use dados históricos quando existirem.
- Revise depois das primeiras semanas.
SLA, prioridade e impacto
Prioridade e impacto ajudam a definir o peso do atendimento. Uma solicitação urgente, que bloqueia a operação, não deve ter o mesmo prazo de uma solicitação administrativa simples. Ao mesmo tempo, nem tudo que o usuário chama de urgente é de fato crítico para a empresa.
Por isso, muitas operações combinam prioridade com categoria, fila ou impacto. Um problema de acesso pode ser urgente para uma área, mas normal para outra. Um documento pendente pode ter prazo curto se impedir faturamento ou prazo maior se for apenas complementar.
O SLA fica mais confiável quando a prioridade é definida por critério e não por pressão. O sistema deve ajudar a padronizar essa leitura, mas a governança do processo precisa explicar quando usar cada nível.
Como acompanhar SLA no dia a dia
Acompanhar SLA não significa olhar apenas o relatório no fim do mês. A gestão precisa enxergar tickets em risco enquanto ainda há tempo de agir. Filtros, dashboard, lista de tickets e notificações ajudam a transformar SLA em rotina operacional.
Tickets próximos do vencimento devem receber atenção antes de estourar. Dependendo do processo, o sistema pode notificar responsável, escalar para gestor, alterar prioridade, mover para outra fila ou adicionar comentário interno para registrar o risco. O objetivo é reduzir surpresa.
Também é importante separar análise operacional de análise gerencial. No dia a dia, a equipe precisa saber o que deve fazer agora. Na gestão, o foco é entender tendência: quais filas atrasam, quais categorias consomem tempo e quais horários concentram mais risco.
- Monitorar tickets em risco.
- Filtrar por SLA estourado.
- Comparar filas e categorias.
- Acompanhar reincidência.
- Usar automações de alerta.
Erros comuns na gestão de SLA
O primeiro erro é aplicar o mesmo prazo para todos os tickets. Isso simplifica a configuração, mas prejudica a operação. O segundo erro é não considerar horário de atendimento. Um ticket aberto à noite não deve ser tratado como atraso se a equipe só trabalha em horário comercial.
Outro erro é usar SLA como ferramenta de punição, e não de gestão. O indicador deve mostrar risco, gargalo e necessidade de ajuste. Se o time passa a esconder ou manipular status apenas para não estourar prazo, o processo perdeu confiança.
Também é comum esquecer de revisar políticas quando filas, prioridades ou categorias mudam. SLA antigo em estrutura nova pode gerar prazos incorretos, relatórios confusos e decisões ruins.
- Prazo único para tudo.
- Ignorar horário útil.
- Não diferenciar prioridade.
- Não revisar políticas antigas.
- Cobrar SLA sem analisar capacidade.
Exemplo prático de matriz de SLA
Uma forma simples de começar é criar uma matriz com três prioridades. Tickets normais podem ter prazo maior, tickets de alta prioridade podem exigir resposta mais rápida e tickets urgentes podem receber monitoramento imediato. A matriz não precisa ser perfeita no primeiro dia; ela precisa ser clara o suficiente para orientar a equipe.
Depois, a empresa pode cruzar prioridade com fila e categoria. Uma solicitação de cadastro pode ter prazo diferente de uma falha que bloqueia faturamento. Uma demanda de suporte interno pode ter prazo diferente de um atendimento externo com impacto direto no cliente. Esse refinamento impede que o SLA seja genérico demais.
O ideal é documentar exemplos reais. Quando a equipe sabe que “nota fiscal pendente”, “acesso bloqueado” ou “documento obrigatório” pertence a uma prioridade específica, a classificação fica mais consistente e os relatórios ficam mais confiáveis.
- Prioridade normal para demandas sem bloqueio imediato.
- Prioridade alta para demandas com impacto operacional relevante.
- Prioridade urgente para casos que impedem execução, faturamento ou atendimento crítico.
- Revisão mensal nos primeiros ciclos de uso.
SLA como comunicação com o solicitante
SLA não serve apenas para controle interno. Ele também melhora a comunicação com o solicitante. Quando o usuário entende que a demanda foi registrada, classificada e possui prazo de atendimento, a ansiedade diminui e a equipe recebe menos cobranças paralelas.
Isso não significa prometer prazos impossíveis. A comunicação precisa ser realista. Em alguns casos, o melhor retorno inicial é explicar que o ticket foi recebido, informar a fila responsável e registrar a próxima etapa. Esse tipo de transparência já melhora muito a percepção de atendimento.
Quando o ticket depende de terceiros, documentos ou validações, o SLA também ajuda a separar tempo da equipe e tempo de espera externa. Essa distinção evita que o indicador seja interpretado de forma injusta e ajuda a identificar gargalos que não dependem apenas do atendente.
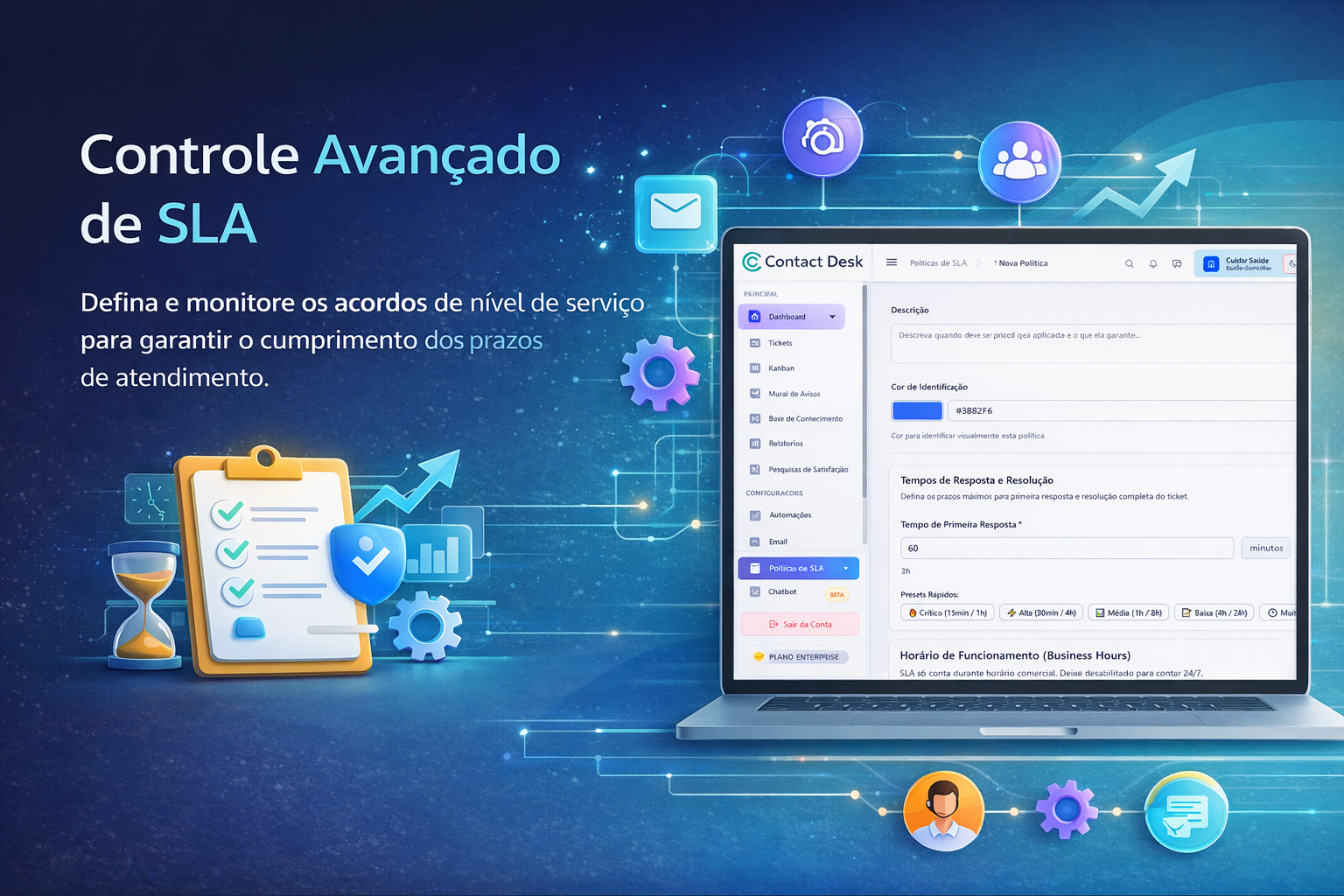
Como o Contact Desk aplica SLA
No Contact Desk, SLA pode ser conectado ao fluxo de tickets para mostrar prazos, risco de atraso e cumprimento por contexto. A operação consegue trabalhar com filas, prioridades, categorias, responsáveis e automações, mantendo o SLA como parte natural do atendimento.
As automações ajudam a agir sobre eventos de risco. Um ticket próximo do vencimento pode gerar notificação, comentário interno, movimentação ou escalonamento. Relatórios e dashboard ajudam a gestão a acompanhar desempenho sem depender de controles manuais.
A proposta é fazer o SLA sair do cadastro estático e entrar na rotina. A equipe vê o prazo dentro do ticket. O gestor acompanha indicadores. A auditoria preserva as mudanças relevantes. Isso torna a gestão de prazo mais transparente.